
IT之家 8 月 7 日音书明日香最新番号,Meta 公司为了缓解当然说话治理(NLP)时代依赖东谈主类注目评估 AI 模子的问题,最新推出了“自学评估器”(Self-Taught Evaluator),讹诈合成数据捕快 AI。
NPU 时代挑战
NPU 时代的发展,鼓动大型说话模子(LLMs)高精度地实施复杂的说话有关任务,竣事更当然的东谈主机交互。
不外现时 NPU 时代面对的一个要紧挑战,即是评估模子严重依赖东谈主工注目。
东谈主工生成的数据关于捕快和考据模子至关要紧,但集结这些数据既花钱又费时。况兼跟着模子的阅兵,昔时集结的注目可能需要更新,从而裁汰了它们在评估新模子时的遵循。
四房色播现在的模子评估门径频繁波及集结无数东谈主类对模子反应的偏好判断。这些门径包括在有参考谜底的任务中使用自动度量,或使用告成输出分数的分类器。
这些门径齐有局限性,尤其是在创意写稿或编码等复杂场景下,可能存在多个灵验恢复,导致了东谈主类判断的高互异问题和高资本。
自学评估器
Meta FAIR 团队推出了名为“自学评估器”的全新神色,不需要东谈主工注目,而是使用合成数据进行捕快。
这一进程从种子模子运转,种子模子会生成对比明白的合成偏好对。然后,模子对这些偏好对进行评估并束缚阅兵,在随后的迭代中讹诈其判断来进步性能。这种门径充分讹诈了模子生成和评估数据的才调,大大减少了对东谈主工注目的依赖。
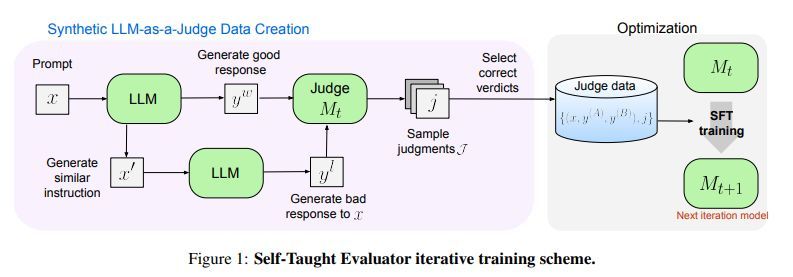
IT之家附上关键设施如下:
1. 使用种子 LLM 为给定教导生成基线反应。
2. 创建教导的修改版块,促使 LLM 生成质料低于原始反应的新反应。
这些配对恢复组成了捕快数据的基础,“自学评估器”看成 LLM-as-a-Judge,为这些配对生成推理轨迹和判断。
通过反复该进程,模子通过自我生成和自我评估的数据束缚进步其判断的准确性,从而灵验地酿成自我完善的轮回。
恶果
Meta FAIR 团队在 Llama-3-70B-Instruct 模子上测试“自学评估器”,在 RewardBench 基准测试中将准确率从 75.4 进步到了 88.7,达到或跳跃了使用东谈主类注目捕快的模子的性能,性能跳跃 GPT-4 等常用大说话模子评审(LLM Judges)。
这一首要阅兵讲明了合成数据在加强模子评估方面的灵验性。此外,盘问东谈主员还进行了屡次迭代明日香最新番号,进一步完善了模子的功能。